In the 7th part of our blog post series “processing GDELT data with SCDF on kubernetes” we will use spring cloud stream’s built-in support for spring cloud functions to implement a sink as a simple consumerfunction.
Since Spring Cloud Stream v2.1, another alternative for defining stream handlers and sources is to use build-in support for Spring Cloud Function where sinks can be expressed as beans of type `Consumer’. Read more about it here in the official documentation of spring cloud stream.
This blogpost will guide you through all necessary steps to implement a spring cloud dataflow (scdf) sink application as a java.util.function.Consumer, including dockerization and deployment on scdf.
It’s recommended to first got through the first part (implementing a source) and the second part ( implementing a processor) as these applications will be used in the example stream.
Source Code
You can find the source code on github:
git clone https://github.com/syscrest/gdelt-on-spring-cloud-data-flow
cd gdelt-on-spring-cloud-data-flow
cd gdelt-article-feed-functional-sink
project setup
The project uses the same project layout and plugins like the functional source application project. Please have a look at the first part (implementing a source) - for a detailed introduction .
Implementation
We want our source application to properly expose its configuration parameters, so we create a dedicated configuration property. The javadoc comment of the members will be displayed as the description and the initial values will automatically noted as the default values (no need to mention them in the javadoc description):
@Component
@ConfigurationProperties("gdelt")
@Validated
public class GDELTArticleSinkProperties {
private boolean printStatistics = true;
public boolean isPrintStatistics() {
return printStatistics;
}
public void setPrintStatistics(boolean printStatistics) {
this.printStatistics = printStatistics;
}
}
The actual spring boot implementation contains our java.util.functions.Consumer that will consume all GDELTArticles and persist them into a database using the spring cloud stream batch mode feature available when executed on kafka. For the sake of simplicity to run this example we do not use an external database but spin up a local in-memory db. After each batch the function will aggregate all articles based on the country and print our some statistics:
@SpringBootApplication
public class GDELTArticleSinkApplication {
Logger logger = org.slf4j.LoggerFactory.getLogger(GDELTArticleSinkApplication.class);
@Autowired
private GDELTArticleSinkProperties configuration;
@Autowired
private JdbcTemplate jdbcTemplate;
public static void main(String[] args) {
SpringApplication.run(GDELTArticleSinkApplication.class, args);
}
@Bean
public JdbcTemplate jdbcTemplate() {
EmbeddedDatabaseFactory factory = new EmbeddedDatabaseFactory();
factory.setDatabaseConfigurer(new MySqlCompatibleH2DatabaseConfigurer());
ResourceDatabasePopulator resourceDatabasePopulator = new ResourceDatabasePopulator();
resourceDatabasePopulator.addScript(new ClassPathResource("schema.sql"));
factory.setDatabasePopulator(resourceDatabasePopulator);
return new JdbcTemplate(factory.getDatabase());
}
@Bean
public Consumer<List<GDELTArticle>> persistArticles() {
return (List<GDELTArticle> articles) -> {
logger.info(String.format("going to add %d articles to h2 database ", articles.size()));
jdbcTemplate.batchUpdate(
"INSERT IGNORE INTO articles "
+ "(language, seendate , sourcecountry , title , url , domain, content) "
+ " VALUES (?, ?, ?, ?, ?, ? ,?) on duplicate key update url = url",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, articles.get(i).getLanguage());
ps.setString(2, articles.get(i).getSeendate());
ps.setString(3, articles.get(i).getSourcecountry());
ps.setString(4, articles.get(i).getTitle());
ps.setString(5, articles.get(i).getUrl());
ps.setString(6, articles.get(i).getDomain());
ps.setString(7, articles.get(i).getContent());
}
@Override
public int getBatchSize() {
return articles.size();
}
});
if (configuration.isPrintStatistics()) {
jdbcTemplate
.queryForList("select sourcecountry , count(*) as total_count "
+ " from articles group by sourcecountry "
+ " order by total_count desc, sourcecountry desc")
.forEach((rowMap) -> {
logger.info(
String.format("country '%s' - current article count = %d",
rowMap.get("sourcecountry"), rowMap.get("total_count")));
});
}
};
}
}
As Spring boot applications are aware of a lot common configuration properties, we create a file named META-INF/spring-configuration-metadata-whitelist.properties to explictly limit the displayed configuration options to our class. Read more about whitelisting here.
configuration-properties.classes=com.syscrest.blogposts.scdf.gdeltsink.GDELTArticleSinkProperties
Spring Cloud Stream functions support (documentation) automatically creates input and output channels based on the function name see docs more more details. As our function is named “persistArticles”, it will create a channel named persistArticles-in-0. But spring cloud data flow is not aware of this channel, it expects a single input channel named input on a sink implementation. So we need to define an alias so it matches the channel name expected by spring cloud data flow:
src/main/resources/application.properties:
spring.cloud.stream.function.bindings.persistArticles-in-0=input
And we also need to tell spring cloud stream which function to use.
src/main/resources/application.properties:
spring.cloud.function.definition=persistArticles
Because we want to use the batch-mode, we need to enable it with:
src/main/resources/application.properties:
spring.cloud.stream.bindings.input.consumer.batch-mode=true
Build the project
You can package the application, create the docker image and upload it to docker-hub with a single command (It requires a docker hub account, please replace the placeholders accordingly).
Note: you could skip this step and use our docker image (syscrest/gdelt-article-feed-functional-sink-hoxton).
./mvnw clean package jib:build \
-Djib.to.auth.username=yourdockerhubaccount \
-Djib.to.auth.password=youdockerhubpassword \
-Dimage=registry.hub.docker.com/yourdockerhubaccount/gdelt-article-feed-functional-sink-hoxton
The output should look like this:
[INFO] Scanning for projects...
[WARNING]
.....
[INFO] --- jib-maven-plugin:1.6.1:build (default-cli) @ gdelt-article-functional-sink ---
[INFO]
[INFO] Containerizing application to registry.hub.docker.com/syscrest/gdelt-article-functional-sink-hoxton...
[INFO]
[INFO] Container entrypoint set to [java, -cp, /app/resources:/app/classes:/app/libs/*, com.syscrest.blogposts.scdf.gdeltsink.GDELTArticleSinkApplication]
[INFO]
[INFO] Built and pushed image as registry.hub.docker.com/syscrest/gdelt-article-functional-sink-hoxton
[INFO] Executing tasks:
[INFO] [=========================== ] 90,0% complete
[INFO] > launching layer pushers
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 26.892 s
[INFO] Finished at: 2020-04-05T23:17:01+02:00
[INFO] ------------------------------------------------------------------------
The docker image has been pushed to hub.docker.com. But we also want to use the metadata-jar (target\gdelt-article-feed-functional-sink-1.0.0-SNAPSHOT-metadata.jar). SCDF can pull jar files not only from maven central but also from any http server, so we uploaded it to our website to make it available for the scdf server (you can find the url in the next section).
Register the app
Browse your Spring Cloud Data Flow UI and select “Apps” and then “+ Add Application”:
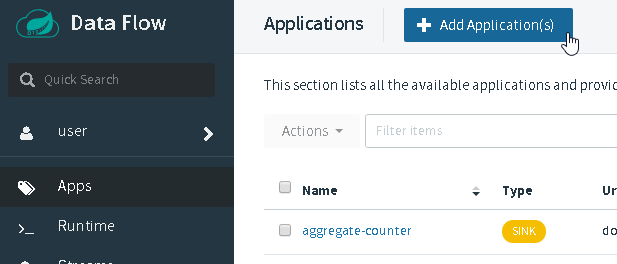
Select “Register one or more applications”:
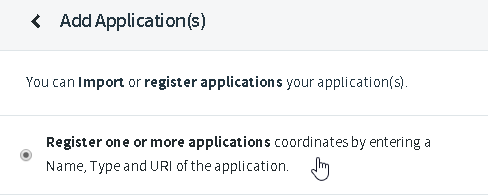
Register the app using:
- Name: gdelt-functional-sink
- Type: Sink
- URI: docker://syscrest/gdelt-article-functional-sink-hoxton:latest
- Metadata URI: https://www.syscrest.com/gdelt-on-scdf-artifacts/gdelt-article-functional-sink-hoxton-metadata.jar
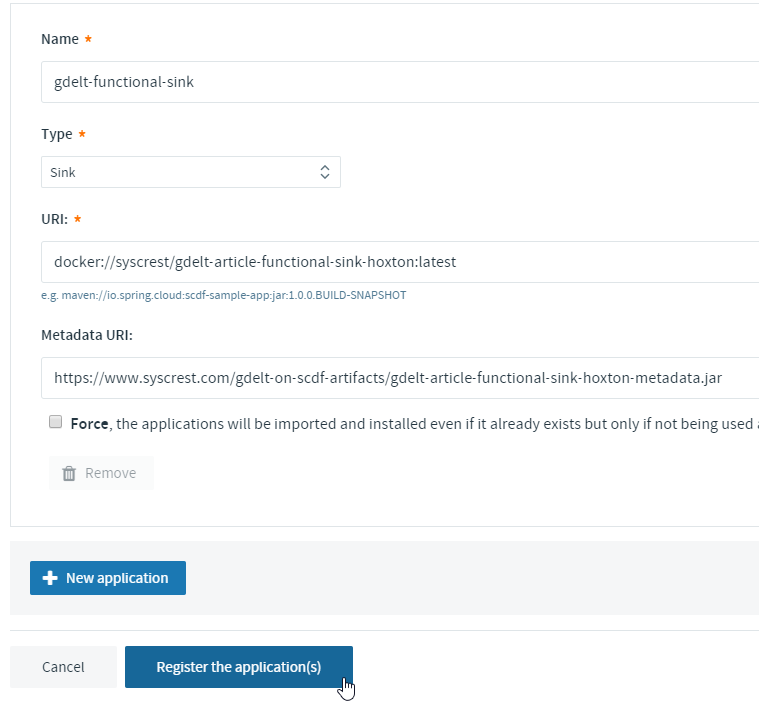
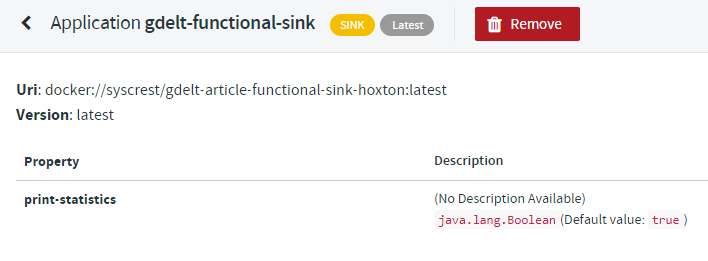
Afterwards browse the application list and click on “gdelt-functional-sink*”:

to verify that all configuration options have been picked up from the metadata jar file:
Creating a stream
Let’s create a simple stream that uses our custom application as the source and use the very basic log processor to just dump the messages into the logfile of a pod. Select Streams on the left sidebar and then click Create stream(s):
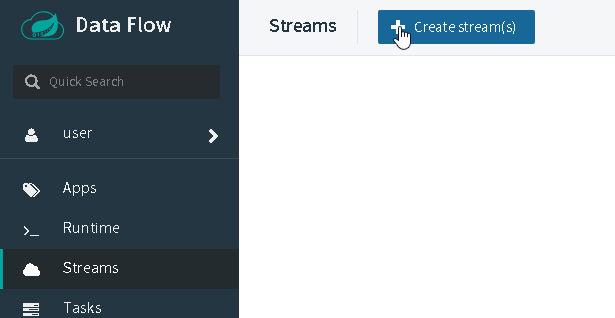
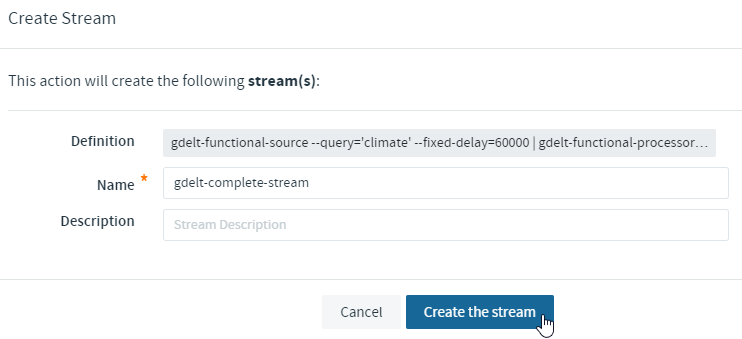
Just copy and paste our example to query all current articles containing ‘climate’ into the textbox:
gdelt-functional-source --query='climate' --spring.cloud.stream.poller.fixed-delay=60000 | gdelt-functional-processor | gdelt-functional-sink

Afterwards save the stream (don’t check ‘Deploy Stream(s)’):
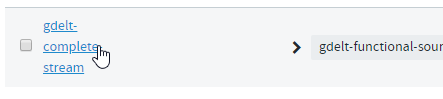
Locate your previously saved stream in the stream list:
When you click on deploy you can define deployment specific settings like memory and cpu assignments, but this is not neccessary. Just hit deploy.

Navigate back to the “streams” section and you will see that your stream is now in the state “deploying” and a couple of minutes later it should be listed as deployed.
Your spring cloud data flow instance will deploy pods in the same namespace it’s running using the stream name plus source/processor names:
kubectl -n scdf-240 get pods
NAME READY STATUS RESTARTS AGE
...
gdelt-complete-stream-gdelt-functional-processor-v1-fb876f4brtc 0/1 Running 0 24s
gdelt-complete-stream-gdelt-functional-sink-v1-75fd8dddfd-rhwxc 0/1 Running 0 23s
gdelt-complete-stream-gdelt-functional-source-v1-5c4d84bf7slvm2 0/1 Running 0 23s
...
Let’s peek into our sink pod to see it in action:
kubectl -n scdf-240 logs -f gdelt-complete-stream-gdelt-functional-sink-v1-75fd8dddfd-rhwxc
and after a couple of minutes it should show some articles counts (these numbers might not change on every update because the stream is not filtering duplicate entries):
.... .GDELTArticleSinkApplication : going to add 1 articles to h2 database
.... .GDELTArticleSinkApplication : country 'United States' - current article count = 4
.... .GDELTArticleSinkApplication : country 'Turkey' - current article count = 1
.... .GDELTArticleSinkApplication : country 'Spain' - current article count = 1
.... .GDELTArticleSinkApplication : country 'Saudi Arabia' - current article count = 1
.... .GDELTArticleSinkApplication : country 'Russia' - current article count = 1
.... .GDELTArticleSinkApplication : country 'New Zealand' - current article count = 1