In the second part of our blog post series “processing GDELT data with SCDF on kubernetes” we will create a custom source application based on spring cloud stream to pull GDELT Data and use it in a very simple flow.
This is an repost of GDELT on SCDF 1.7.0 : Implementing a reactive source application to update instructions and code from SCDF 1.7.0 to 2.2.0.
Source Code
You can find the source code on github:
git clone https://github.com/syscrest/gdelt-on-spring-cloud-data-flow
cd gdelt-on-spring-cloud-data-flow
git checkout scdf-2-2-0
cd gdelt-article-feed-source
maven project setup
The project will be based on Spring Cloud Stream and we wil use the spring cloud dependency management with the latest spring cloud relase Greenwich.RELEASE:
<properties>
<spring-cloud.version>Greenwich.RELEASE</spring-cloud.version>
</properties>
...
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Even if the implementation itself is not kafka-specific (more on binder abstraction) we include the Spring Cloud Kafka Binder directly in our project to build artifacts deployable on our target setup (Kubernetes + Kafka). We also add reactive programming support to leverage the Java Integration DSL for our source implementation.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-reactive</artifactId>
<optional>true</optional>
</dependency>
Use the spring boot maven plugin to package the application itself:
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
Besides the actual fat jar (that will be dockerized later on) we also want to create a so called “metadata-only” jar using the Spring Cloud Stream & Task Metadata Plugin to aggregate spring boot metadata into a seperate lightweight jar. As we are using kubernetes as our deployment target we need to provide docker-based artifacts for deployment. Spring cloud data flow can not determine the actual configuration properties of an application directly from the docker image, but you can provide an additional jar besides the docker image to provide the necessary metadata about configuration options (names, descriptions, default values).
<plugin>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-app-starter-metadata-maven-plugin</artifactId>
<executions>
<execution>
<id>aggregate-metadata</id>
<phase>compile</phase>
<goals>
<goal>aggregate-metadata</goal>
</goals>
</execution>
</executions>
</plugin>
Dockerize the spring boot application using Google’s JIB Maven Plugin:
<plugin>
<groupId>com.google.cloud.tools</groupId>
<artifactId>jib-maven-plugin</artifactId>
<version>1.6.1</version>
<configuration>
<useOnlyProjectCache>true</useOnlyProjectCache>
<to>
<image>registry.hub.docker.com/syscrest/gdelt-article-feed-source-greenwich</image>
</to>
</configuration>
</plugin>
Implementation
Spring Cloud Stream provides a couple of ways to implement a source application. Besides native spring cloud stream annotation you are also free to use Spring Integration. As Spring deprecated spring-cloud-stream-reactive, we reworked the old example for 1.7.0 based on Spring Integration Java DSL to Spring Cloud Function
@EnableConfigurationProperties(GDELTSourceProperties.class)
@EnableBinding(Source.class)
@SpringBootApplication
public class GDELTSourceApplication {
@Autowired
private GDELTSourceProperties properties;
@StreamEmitter
@Output(Source.OUTPUT)
@Bean
public Publisher<Message<List<GDELTArticle>>> emit() {
return IntegrationFlows.from(() -> {
try {
URL feedUrl = new URL("https://api.gdeltproject.org/api/v2/doc/doc?query="
+ URLEncoder.encode(properties.getQuery(), "UTF-8")
+ "&mode=artlist&maxrecords=250×pan=1h&sort=datedesc&format=json");
logger.info("going to fetch data from gdeltproject.org using url = " + feedUrl);
InputStream inputStreamObject = feedUrl.openStream();
BufferedReader streamReader = new BufferedReader(new InputStreamReader(inputStreamObject, "UTF-8"));
StringBuilder responseStrBuilder = new StringBuilder();
String inputStr;
while ((inputStr = streamReader.readLine()) != null) {
responseStrBuilder.append(inputStr);
}
JSONObject jsonObject = new JSONObject(responseStrBuilder.toString());
JSONArray articles = jsonObject.getJSONArray("articles");
List<GDELTArticle> response = new ArrayList<>();
for (int i = 0; i < articles.length(); i++) {
JSONObject article = articles.getJSONObject(i);
GDELTArticle a = new GDELTArticle();
a.setUrl(article.getString("url"));
a.setTitle(article.getString("title"));
a.setDomain(article.getString("domain"));
a.setSourcecountry(article.getString("sourcecountry"));
a.setLanguage(article.getString("language"));
a.setSeendate(article.getString("seendate"));
response.add(a);
}
return new GenericMessage<>(response);
} catch (Exception e) {
logger.error("", e);
return new GenericMessage<>(null);
}
}, e -> e.poller(p -> p.fixedDelay(this.properties.getTriggerDelay(), TimeUnit.SECONDS))).toReactivePublisher();
}
We want our source application to properly expose it’s configuration parameters, so we create a dedicated configuration property. The javadoc comment of the members will be displayed as the description and the initial values will automatically noted as the default values (no need to mention them in the javadoc description):
package com.syscrest.blogposts.scdf.gdeltsource;
...
@ConfigurationProperties("gdelt")
@Validated
public class GDELTSourceProperties {
/**
* The query to use to select data.
*
* Example: ("climate change" or "global warming")
*
*/
private String query = "climate change";
/**
* The delay between pulling data from gdelt (in seconds).
*/
private long triggerDelay = 120L;
/* ... setter and getter omitted ... */
}
As Spring boot applications are aware of a lot common configuration properties, we create a file named META-INF/spring-configuration-metadata-whitelist.properties to explictly limit the displayed configuration options to our class. Read more about whitelisting here.
configuration-properties.classes=com.syscrest.blogposts.scdf.gdeltsource.GDELTSourceProperties
Build the project
You can package the application, create the docker image and upload it to docker hub with a single command (It requires a docker hub account, please replace the placeholders accordingly).
Note: you could skip this step and use our docker image (syscrest/gdelt-article-feed-source-greenwich).
./mvnw clean package jib:build \
-Djib.to.auth.username=yourdockerhubaccount \
-Djib.to.auth.password=youdockerhubpassword \
-Dimage=registry.hub.docker.com/yourdockerhubaccount/gdelt-article-feed-source
The output should look like this:
....
....
[INFO]
[INFO] Containerizing application to syscrest/gdelt-article-feed-source...
[INFO]
[INFO] Retrieving registry credentials for registry.hub.docker.com...
[INFO] Building classes layer...
[INFO] Building resources layer...
[INFO] Getting base image gcr.io/distroless/java...
[INFO] Building dependencies layer...
[INFO] Finalizing...
[INFO]
[INFO] Container entrypoint set to [java, -cp, /app/resources/:/app/classes/:/app/libs/*, com.syscrest.blogposts.scdf.gdeltsource.GDELTSourceApplication]
[INFO]
[INFO] Built and pushed image as syscrest/gdelt-article-feed-source-greenwich
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
The docker image has been pushed to hub.docker.com. But we also want to use the metadata jar (target/gdelt-article-feed-source-1.0.0-SNAPSHOT-metadata.jar). SCDF can pull jar files not only from maven central but also from any http server, so we uploaded it to our website to make it available for the scdf server (you can find the url in the next section).
Register the app
Browse your Spring Cloud Data Flow UI and select “Apps” and then “+ Add Application”:
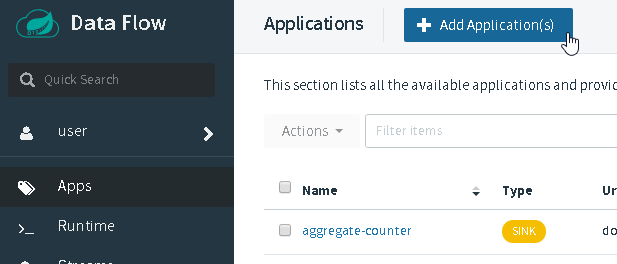
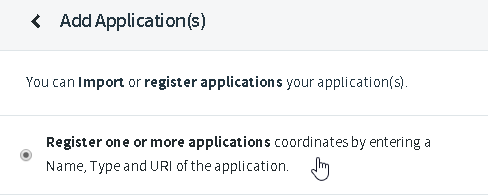
Select “Register one or more applications”:
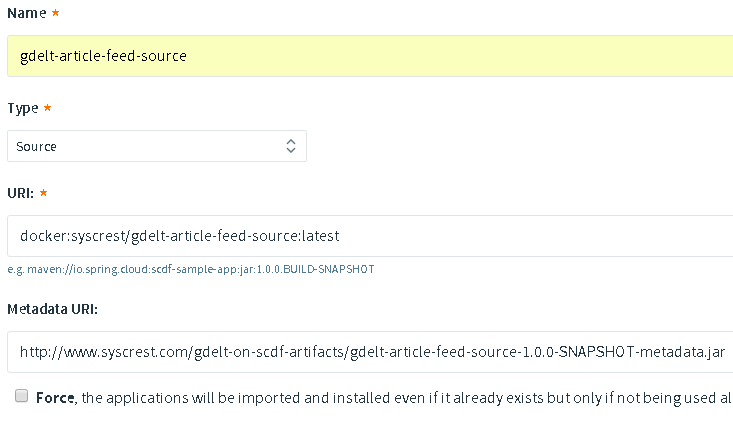
 Register the app using:
Register the app using:
- Name: gdelt-article-feed-source
- Type: Source
- URI: docker:syscrest/gdelt-article-feed-source-greenwich:latest
- Metadata URI: https://www.syscrest.com/gdelt-on-scdf-artifacts/gdelt-article-feed-source-greenwich-metadata.jar
 Afterwards browse the application list and click on “gdelt-article-feed-source”:
Afterwards browse the application list and click on “gdelt-article-feed-source”:

to verify that all configuration options have been picked up from the metadata jar file:

Creating a stream
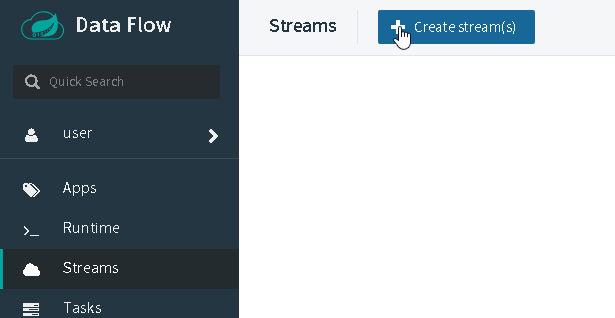
Let’s create a simple stream that uses our custom application as the source and use the very basic log processor to just dump the messages into the logfile of a pod. Select Streams on the left sidebar and then click Create stream(s):
Just copy and paste our example to query all current articles containing ‘climate change’ into the textbox:
gdelt-article-feed-source --trigger-delay=300 --query='climate change' | log
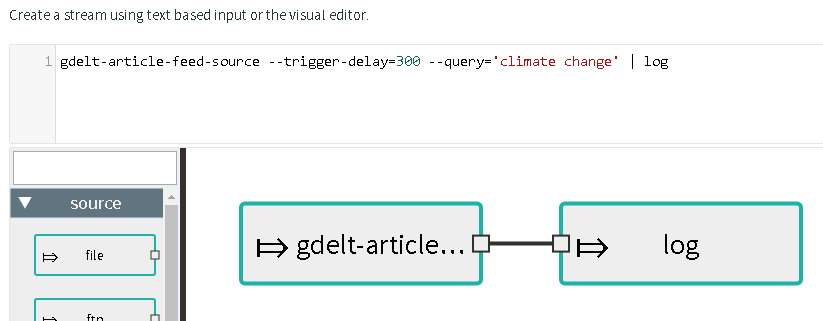
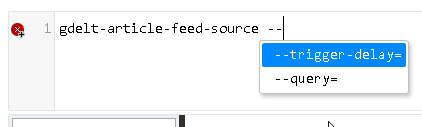
You can also just type and use the autocompletion:
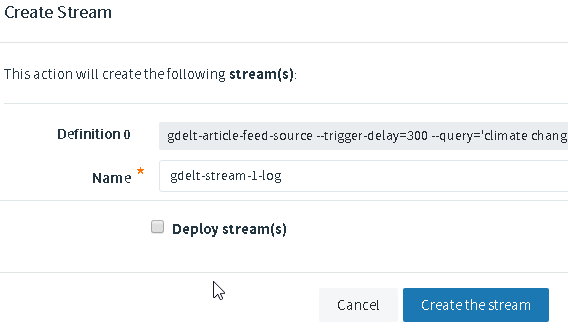
Afterwards save the stream (don’t check ‘Deploy Stream(s)’):
Locate your previously saved stream in the stream list:

When you click on deploy you can define deployment specific settings like memory and cpu assignments (not necessary , default values are sufficient):

Navigate back to the “streams” section and you will see that your stream is now in the state “deploying”:

After a couple of minutes it should be listed as “deployed”:

Your spring cloud data flow instance will now deploy pods in the same namespace it’s running using the stream name plus source/processor names:
kubectl -n scdf-220 get pods
NAME READY STATUS RESTARTS AGE
...
gdelt-stream-1-log-gdelt-article-feed-source-6c457dfb9f-v28ls 0/1 Running 0 1m
gdelt-stream-1-log-log-64cfc8bc-bb6n9 0/1 Running 0 1m
...
Let’s peek into the “log” pod the see the data that has been emitted by our custom source:
kubectl -n scdf-220 logs -f gdelt-demo-1-log-7999bb94d8-9dcw6
output (reformatted for better readability):
2018-11-30 23:06:03.447 INFO 1 --- [container-0-C-1] log-sink
:
[
...
{
"url":"https://www.rga.de/politik/angela-merkel-nach-g20-forbes-kuert-sie-zur-maechtigsten-frau-welt-news-zr-10773201.html",
"title":"Angela Merkel nach G20 : „ Forbes kürt sie zur mächtigsten Frau der Welt - News",
"language":"German",
"sourcecountry":"Germany",
"domain":"rga.de",
"seendate":"20181205T113000Z"
},
{
"url":"https://www.vienna.at/cop24-raet-wegen-klimawandel-zur-weniger-fleischkonsum/6022139",
"title":"COP24 rät wegen Klimawandel zur weniger Fleischkonsum",
"language":"German",
"sourcecountry":"Austria",
"domain":"vienna.at",
"seendate":"20181205T113000Z"
},
...
...
]
Let’s create a slightly improved version that splits the array of GDELTArticle into separate messages using the splitter starter app and channel these messages into an explicit topic named climate-change-articles:
gdelt-article-feed-source --query='climate change' | splitter --expression="#jsonPath(payload,'$.*')" > :climate-change-articles

If you peek into the topic you can see that each message just contains a single article:
{"url":"https://advertisingmarket24.com/biomass-power-generation-market-global-industry-analysis-size-share-growth-trends-and-forecast-2018-2022/807358/","title":"Biomass Power Generation Market – Global Industry Analysis , Size , Share , Growth , Trends and Forecast 2018 – 2022 – Advertising Market","language":"English","sourcecountry":"","domain":"advertisingmarket24.com","seendate":"20181205T120000Z"}
{"url":"https://www.princegeorgecitizen.com/news/national-news/in-the-news-today-dec-5-1.23519640","title":"In the news today , Dec . 5","language":"English","sourcecountry":"Canada","domain":"princegeorgecitizen.com","seendate":"20181205T120000Z"}
{"url":"https://www.zazoom.it/2018-12-05/manovra-rivoluzione-congedo-parentale-si-potra-lavorare-fino-al-parto/4953509/","title":"Manovra | rivoluzione congedo parentale Si potrà lavorare fino al parto","language":"Italian","sourcecountry":"Italy","domain":"zazoom.it","seendate":"20181205T120000Z"}
{"url":"http://www.businessghana.com/site/news/business/177668/AfDB,-AGTF-to-provide-funds-for-NEP","title":"AfDB , AGTF to provide funds for NEP - BusinessGhana News","language":"English","sourcecountry":"Ghana","domain":"businessghana.com","seendate":"20181205T120000Z"}
{"url":"http://visayandailystar.com/2018/December/05/overview.htm","title":"Daily Star Opinions : Overview with Gwyne Dyer","language":"English","sourcecountry":"Philippines","domain":"visayandailystar.com","seendate":"20181205T120000Z"}
You will notice that calling the gdelt endpoint continuously will result in a lot of duplicate articles. We will fix this in the next blog post, where we will implement a custom filter processor to introduce a very basic deduplication.