How to use Accumulos RangePartioner to increase your mr-job ingest rate (and the neccessary pieces to include it into an oozie worflow)
In Hadoop, HashPartitioner is used by default to partition the datasets among different reducers. This is done by hashing the keys to distribute the data evenly between all reducers and then sorting the data within each reducer accordingly. While this works just fine, if you were running a map reduce job that writes data into an existing Accumulo table, HashPartitioner would lead to each reducer writing to every tablet (sequentially). In this case, you might want to configure your MapReduce job to use RangePartitioner for an improved job’s write performance and therefore increase its speed. In this blog, we are going to discuss how to configure your job to use RangePartitioner as its partitioner, and, - assuming that you are running the job as part of a worklow - , how to incorporate it in Oozie.
Increasing ingestion by decreasing congestion / leveling parallelism
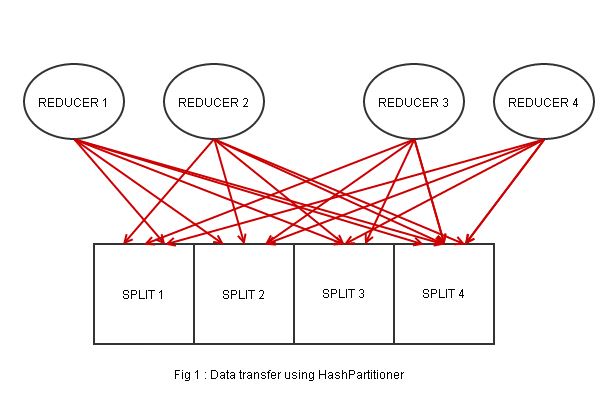
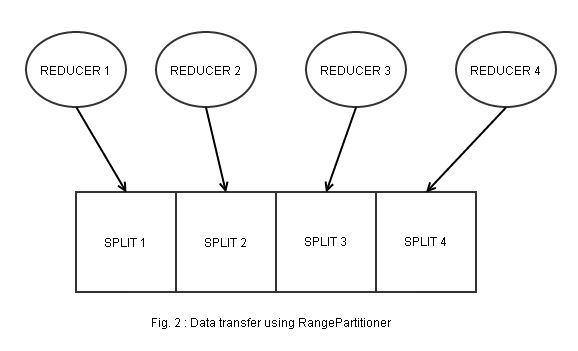
When you are setting up a Hadoop job to process a large dataset and write into an Accumulo table, there’s data transfer between the reducers and Accumulo TabletServers, which then adds the key value pairs to the appropriate tablet. Now, as mentioned earlier, if you don’t specify any partitioner class in the job configuration, Hadoop will use the HashPartitioner to partition your data and you would have your data spread into a number of reducers, sorted by the hash value. However, citing the Accumulo User Manual**, **Accumulo tables are partitioned into tablets consisting a set of key value pairs, sorted lexicographically in ascending order. Comparing the two, we can intuitively say that the reducer and Accumulo have 2 different sorting methods. By using HashPartitioner, one reducer ends up containing different key values for every tablets, and each key value pair needs to undergo another “checking” before it is sent to the appropriate tablet (Fig. 1). This would cost you a lot of time and your reduce-slots will probably congest single tablets, slowing down ingestion. As with RangePartitioner, on the other hand, you could ensure that during the MapReduce job, the data are partitioned the same way as in Accumulo, so each reducer ends up with only key-value pairs for each tablet (Fig. 2).
When using a RangePartitioner it will NOT increase your job execution time
Using a RangePartitioner can increase your data ingest rate, but be aware of your data distribution. If your data is distributed very unevenly you might end up with a lot of Reducers doing almost nothing and very few reducers doing all the work, killing the parallelism in your job and driving your ingestion rate down (Fig. 3). In that case, HashPartioner might be a better choice.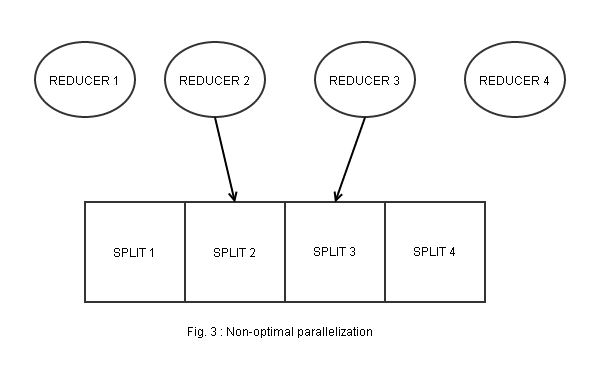
Configuring a RangePartitioner in a mapreduce job
To set your map reduce job to use RangePartitioner, you will need to do the following:
1. Write all split points (base64) of the Accumulo table in a file on HDFS
2. Pick up the number of splits in the Accumulo table to determine the number of reducers needed for your job. For example, if there are 10 split points, you will need 10 + 1 = 11 reducers,
3. Use [ RangePartitioner.setSplitsFile()](http://accumulo.apache.org/1.7/apidocs/org/apache/accumulo/core/client/mapreduce/lib/partition/RangePartitioner.html#setSplitFile%28org.apache.hadoop.mapreduce.Job,%20java.lang.String%29) and [Job.setNumReduceTasks()](https://hadoop.apache.org/docs/r1.0.4/api/org/apache/hadoop/mapreduce/Job.html#setNumReduceTasks%28int%29) to configure your job
Hint: If you take a look at the source code of RangePartitioner.setSplitsFile() you will notice that the file path is added to the job configuration and the file is added to the distributed cache.
Configuring a RangePartitioner in an oozie workflow
Since RangePartioner requires some custom action to create an up-to-date splits file and determine the current number of splits, you will need a custom java action in your oozie workflow before the actual mapreduce action can be executed. From within your Java Action you can use “capture-output” and (see this blog post for futher details).
So add a custom java action to your project that creates the appropriate splits file and that propagates the neccessary configuration for the subsequent actions:
package mypgk;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintStream;
import java.util.Collection;
import java.util.Properties;
import org.apache.accumulo.core.cli.ClientOnRequiredTable;
import org.apache.accumulo.core.client.AccumuloException;
import org.apache.accumulo.core.client.AccumuloSecurityException;
import org.apache.accumulo.core.client.Connector;
import org.apache.accumulo.core.client.TableNotFoundException;
import org.apache.accumulo.core.util.TextUtil;
import org.apache.commons.codec.binary.Base64;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
public class SplitsFileAction {
public static String OOZIE_ACTION_OUTPUT_PROPERTIES = "oozie.action.output.properties";
static class Opts extends ClientOnRequiredTable {
@Parameter(names = "--targetFile", required = true)
String targetFile;
}
public static void main(String[] args) throws TableNotFoundException,
AccumuloSecurityException, AccumuloException, IOException {
Opts opts = new Opts();
opts.parseArgs(CreateSplitsFileAction.class.getName(), args);
Connector connector = opts.getConnector();
Path targetFile = new Path(opts.targetFile);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
PrintStream out = new PrintStream(new BufferedOutputStream(
fs.create(targetFile)));
Collection splits = connector.tableOperations().listSplits(
opts.tableName);
for (Text split : splits)
out.println(new String(
Base64.encodeBase64(TextUtil.getBytes(split))));
out.close();
String oozieProp = System.getProperty(OOZIE_ACTION_OUTPUT_PROPERTIES);
OutputStream os = null;
if (oozieProp != null) {
File propFile = new File(oozieProp);
Properties p = new Properties();
p.setProperty("reducer_count", "" + (splits.size() + 1));
p.setProperty("splits_file", targetFile.toString());
os = new FileOutputStream(propFile);
p.store(os, "");
os.close();
} else {
throw new RuntimeException(OOZIE_ACTION_OUTPUT_PROPERTIES
+ " System property not defined");
}
}
}
and integrate it into your workflow:
<action name="split-file-action">
<java>
<main-class>mypkg.SplitsFileAction </main-class>
<arg>-z</arg>
<arg>${zookeeperHost}</arg>
<arg>-i</arg>
<arg>${accumuloInstance}</arg>
<arg>-u</arg>
<arg>${accumuloUser}</arg>
<arg>-p</arg>
<arg>${accumuloPassword}</arg>
<arg>--table</arg>
<arg>${accumuloTable}</arg>
<arg>--targetFile</arg>
<arg>/tmp/${wf:id()}/${accumuloTable}_splits.txt</arg>
<capture-output />
</java>
<ok to="mapreduce-action"/>
<error to="fail"/>
</action>
Now you can pick up the neccessary configuration in your mapreduce action:
<map-reduce>
...
<configuration>
<property>
<name>mapreduce.partitioner.class</name>
<value>org.apache.accumulo.core.client.mapreduce.lib.partition.RangePartitioner</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>${wf:actionData('split-file-action’))['reducer_count']}</value>
</property>
<property>
<name>org.apache.accumulo.core.client.mapreduce.lib.partition.RangePartition er.cutFile</name>
<value>${wf:actionData('split-file-action’))['splits_file']}</ </value>
</property>
</configuration>
<file>${wf:actionData('split-file-action’))['splits_file']}</file>
</map-reduce>